HowTo guide for developers¶
This page is intended as a quick reference to solve some of the problems that are commonly encountered when developing within the Abinit project.
How to generate the configure script via makemake¶
Abinit uses the standard configure && make approach to build from source. Note, however, that the developmental version does not contain the configure script. To generate the configure script and the other files required by the build system, you need to execute makemake:
cd ~abinit
./config/scripts/makemake
makemake requires a recent version of the python interpreter as well as m4, autoconf, and automake. If these tools are not installed on your machine, you need to compile them from source or use your preferred package manager to install them. I usually use the conda package manager and:
conda install m4 autoconf automake -c conda-forge
Important
Remember to run makemake every time you add/remove a Fortran file or a new directory or you change parts the buildsystem i.e. the files in ~abinit/config.
How to build Abinit¶
Developers are invited to build the executables inside a build directory i.e. a directory that is separated
from the source tree in order to keep the source directory as clean as possible and allow for multiple builds.
I usually use the naming scheme: _build_[compiler_name] for the build directory and an external file
(e.g. gcc.ac) storing the configuration options that can be passed to configure via the –with-config-file option:
mkdir _build_gcc
cd _build_gcc
../configure --with-config-file=gcc.ac
make -j8 # use 8 processes to compile
Note that the name of the options in the config-file is in normalized form that is:
- Remove the initial
--from the name of the option - Replace
-with underscore_everywhere
For instance, --with-mpi-prefix in normalized form becomes with_mpi_prefix.
Examples of configuration files for clusters can be found in the abiconfig package.
A detailed description of the configuration options supported by the build system is given in this guide by Marc:
Once the build is completed, it is a good idea to check whether the executable works as expected by running the tests in the v1 directory with:
cd tests
../../tests/runtests.py v1 -j4
As usual, use:
../../tests/runtests.py --help
to list the available options. A more detailed discussion is given in this page.

Tip
Remember to run the tests as frequently as possible while developing new features in order to spot possible regressions or incompatibilities. Trust me, you can save a lot of time if you run runtests.py systematically!
How to browse the source files¶
The HTML documentation generated by Robodoc is available at this page.
If you need a tool to navigate the Abinit code inside the editor, I would sugest exuberant-ctags.
To generate a tags file containing the list of procedures, modules, datatypes for all files inside ~abinit/src, use:
cd ~abinit/src
ctags -R
Now it is possible to open the file containing the declaration of the dataset_type Fortran datatype directly from the terminal with:
vi -t dataset_type
Inside the editor, you can go directly to a tag definition by entering the following in vim command mode:
:tag dataset_type
More tips for vim users are available here.
For emacs see this page.
Finally, one can use the abisrc.py script in the ~abinit directory.
TODO
How to debug with gdb¶
Load the executable in the GNU debugger using the syntax:
gdb path_to_abinit_executable
Run the code with the gdb run command and redirect the standard input with:
(gdb) run < run.files
Wait for the error e.g. SIGSEGV, then print the backtrace with:
(gdb) bt
Display additional information of a selected stack frame (the first one here), such as function arguments before the error, with the commands:
(gdb) select-frame 1
(gdb) info args
Tip
Remember to compile the code with the -g option. Avoid debugging code compiled with -O3.
In some tricky cases, you may need to resort to -O0 or use Fortran print statements to avoid miscompilation.
Tip
For debugging MPI jobs, serial debuggers attached to individual processes are useful.
Run an MPI job (4 processes in this example) that opens separate instances of xterm terminal windows
for individual processes and then loads the ABINIT executable in the GNU debugger on each one of them, using
the command:
mpirun -n 4 xterm -e gdb path_to_abinit_executable
Run ABINIT on each process separately by typing the following command on every terminal window opened during the previous step:
(gdb) run path_to_input_abi
Within each process, gdb can be used as in the serial case.
For a more complete introduction to gdb, we suggest this youtube tutorial:
How to add a new Fortran file¶
- Create the F90 module and
git addit - Register the F90 file in the
abinit.srcfile (avoid duplicated names in the public API, abisrc.py will complain about that) - Register the F90 file in the
CMakeLists.txtfile as well - Rerun
makemakein the source directory - Rerun
configureandmakein the build directory (possiblymake clean && make)
How to add a new Abinit input variable¶
This section documents the procedure required to add a new Abinit input variable. To make things as simple as possible, we ignore the (more complicated) case of dimensions such as nkpt or nsym whose value may depend on the dataset. To add a new variables follow the below steps:
-
Add the new variable to dataset_type. Remember that the name cannot end with a digit as this enters into conflict with the multidataset syntax.
-
The default value of the new input variable can be specified in two different ways:
- in the declaration of the Fortran type if the size is known at compile time and the initial value does not depend on other variables.
- in the indefo routine if the value must be computed at runtime.
-
Add the name of the new variable to chkvars.
-
Add a new section to dtset_copy to copy the new variable (use alloc_copy if allocatable).
-
If you need an allocatable entity, remember to deallocate memory in dtset_free.
-
Read the variable in the invars2 (if it is not a basic dimension).
-
Change one of the outvars routines (outvar_a_h, outvar_i_n, outvar_o_z) to print the variable according to the first letter of the new variable
-
The logic for checking the consistency of input variables goes to chkinp. Use the routines chkint_eq, chkint_ne, chkint_ge, chkint_le, chkdpr.
-
Add the documentation of the new variable to
~abinit/abimkdocs/variables_CODE.pyfollowing the instructions given in this section.
Finally,
make clean && make -j8
since you broke the ABI of a public datastructure and all the object files depending on this datastructure must be recompiled (if you are developing a library, you should release a new major version!)
No, it’s not a typo, ABIs and APIs are two different concepts! From this answer on stackoverflow
If you expand, say, a 16-bit data structure field into a 32-bit field, then already-compiled code that uses that data structure will not be accessing that field (or any following it) correctly. Accessing data structure members gets converted into memory addresses and offsets during compilation and if the data structure changes, then these offsets will not point to what the code is expecting them to point to and the results are unpredictable at best.
For the treatment of dimensions see invars0, invars1m
How to add a new test in the test suite¶
Please see the testsuite documentation.
Code Coverage¶
In computer science, code coverage is a measure used to describe the degree to which the source code of a program is tested by a particular test suite. A program with high code coverage has been more thoroughly tested and has a lower chance of containing software bugs than a program with low code coverage. Many different metrics can be used to calculate code coverage; some of the most basic are the percent of program subroutines and the percent of program statements called during execution of the test suite. We aim that the test suite covers all the functionalities of ABINIT.
How to trigger a coverage report?
There is one slave dedicated to on-demand execution of branches by the developers that produces a code coverage report, at present, higgs_gnu_7.5_cov. It can be launched by the general on-demand interface (contact Jean-Michel or Xavier if you do not yet have access to it). Code coverage reports from recent runs of the tests are available here. If you see parts of the code which are not well tested, please contribute to improving coverage by writing new tests!
Info
How does it work?
ABINIT is built with special options such that every function that is executed in the program
is mapped back to the function points in the source code.
A .gcno file is generated when the source file is compiled with the GCC -ftest-coverage option.
It contains information to reconstruct the basic block graphs and assign source line numbers to blocks.
More info are available in the Gvoc page.
A .gcda file is generated when a program containing object files built with the GCC -fprofile-arcs option is executed.
A separate .gcda file is created for each object file compiled with this option.
It contains arc transition counts, and some summary information.
Finally, we use lcov to analyze the .gcda files for generating a html report
How to fix Robodoc warnings¶
The following section is aimed at helping developers to solve problems related to robodoc error messages. It comes from the file doc/developers/robodoc.doc.txt
A robodoc section must always start with a “begin marker” and end with a “end marker”. In ABINIT, the begin marker is usually:
!!****f*
or
!!****m*
while the end marker is always
!!***
A common problem when generating .html for ABINIT thanks to Robodoc, is the lack of an end marker for each begin marker. The solution is simple: find the end of the robodoc section (often, either the end of file, or just before the next begin marker), and insert
!!***
How to make the parents script happy¶
The script parents relies heavily on the Robodoc-type structuration of the source file. In particular, a source file should be made of sets of robodoc blocks, possibly separated by comments or blank lines.
In most of the source files, one block relates to a subroutine, typically:
!!****f* ABINIT/name_of_subroutine
!! NAME
!! name_of_subroutine
<...>
subroutine name_of_subroutine
<...>
!!***
The most common source of errors comes from the fact that the parent.pl script expects the name_of_subroutine to be coherent in the three above occurrences. In this case, you should get something like:
Error: Robodoc subroutine NAME missing in <dir/name_of_routine.F90>
For example, the following will generate an error
!!****f* ABINIT/blabla
!! NAME
!! blabla
<...>
subroutine blabla_int
<...>
!!***
It will be easy to correct this piece of code:
!!****f* ABINIT/blabla_int
!! NAME
!! blabla_int
<...>
subroutine blabla_int
<...>
!!***
Unfortunately, in some ABINIT source files, the number of such blocks can be large (bigger than 10), and the above-mentioned error message does not mention the line where the error was found, neither the subroutine for which there has been a mismatch. How to find the place where the error occurred?
In the full list of messages obtained when executing
make parent
one can find the list of block in this source file for which make parent succeeded.
The suggestion is thus to examine the list of blocks or subroutines (e.g. grep ‘end subroutine’), and proceed by elimination: the one that failed is the only one who did not succeed. Sorry if this procedure is not very nice.
Q2 How to debug if a section of the source file disappeared?
Answer: Well, it is likely that you have forgotten the keyword
SOURCE
after the section CHILDREN.
How to make the abiauty script happy¶
After executing
make abiauty
in the src directory, one can get several types of messages. However, they are not always very indicative of what should be corrected. Here follows a set of hints to fix the problem identified by abiauty.
SOME INFORMATION¶
The goal of abiauty is to indent correctly the lines inside the F90 source files of ABINIT. In order to do this, the F90 source files must respect some rules. It will be quite long to explain them. You can get a feeling by simply looking at existing files!
The script abiauty relies heavily on the structuration of the source file. In particular, after a section where variables are declared, abiauty expects the following line:
! *************************************************************************
namely, a ‘!’, then a blank, then 73 stars - copy it from here, it is the simplest.
In the above mentioned case, such a line was missing at the line 138 of the file 32_util/interpol3d.F90, preventing abiauty to understand the structure of the file.
More explicitly, here is the old section (that does not follow the abirules):
real(dp) :: d1,d2,d3
d1=one/nr1
And here is the new section (that follows the abirules):
real(dp) :: d1,d2,d3
! *************************************************************************
d1=one/nr1
Questions¶
Q1: How to debug ABINIT when he following diagnostic is obtained
ERROR(66_paw/qijb_bk.F90):
found end statement at line 183 for '' subroutine '' instead of '' subroutine qijb_bk ''
Answer:
Simply, you have not mentioned the name of the routine at the “end subroutine statement”. So, in the routine name_of_routine.F90, replace:
end subroutine
by
end subroutine name_of_routine
Q2: How to debug ABINIT when the following diagnostics are obtained
ERROR(72_response/nstpaw3.F90):
found end statement at line 652 for '' if '' instead of '' do construct ''
ERROR(42_parser/instrng.F90):
found end statement at line 316 for '' subroutine instrng '' instead of '' do construct ''
Answer:
There are some fundamental limitations of the abiauty script, moreover accompanied with a diagnostic that is of no help.
(1) abiauty cannot treat an “if” statement, followed by a conditional that is split on two lines, with moreover, a comment at the end of the first line. E.g. it cannot treat:
if( conditional1 .and. & ! Here is a comment, that cannot be treated correctly by abiauty
& conditional2 ) then
You can choose between different possibilities avoid this problem:
! Here is a comment BEFORE the if
if( conditional1 .and. &
& conditional2 ) then
or
if( conditional1 .and. conditional2 ) then ! Here is a comment for the whole line
or
if( conditional1 .and. &
& conditional2 ) then ! Here is a comment for the split line
(2) in certain cases, abiauty cannot treat a “call” that appears immediately after a “if”. E.g it cannot treat:
if (condition) call name_of_subroutine
You have to replace it by
if (condition) then
call name_of_subroutine
endif
(3) abiauty cannot treat a “enddo” that appears on the same line than another command thanks to a “;”. E.g. it cannot treate:
do ii=1,nn ; mm=mm+ii ; enddo
You have to replace it by
do ii=1,nn
mm=mm+ii
enddo
The indication of the line where the script realizes that there is a problem, is not the indication of the line at which the problem occurs. However, the abiauty script identifies also, earlier, that there is a problem with this line. Typically, the two error messages appear:
ERROR(42_parser/instrng.F90):
semicolon found at line 102 with do statement
ERROR(42_parser/instrng.F90):
found end statement at line 103 for '' if '' instead of '' do construct ''
or
ERROR(42_parser/instrng.F90):
semicolon found at line 101 with do statement
ERROR(42_parser/instrng.F90):
found end statement at line 316 for '' subroutine instrng '' instead of '' do construct ''
Suggestion: examine first the ‘semicolon found at line 102 with do statement’ error message.
Q3: How to debug ABINIT when the following diagnostic is obtained:
ERROR(95_drive/timana.F90):
semicolon found at line 853 with case(1) statement
Answer:
Following the abirules, one should not have the following syntax:
case(xx) ; instruction
The instruction should instead appear in the line following the case condition:
case(xx)
instruction
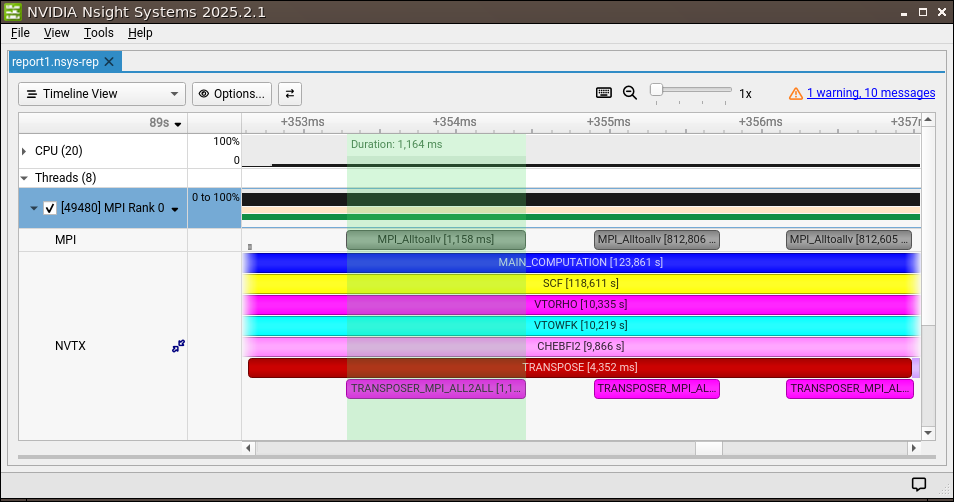
How to profile MPI jobs using NVTX/Nsight¶
Among tools that analyze MPI usage and performance, it is possible to annotate source code using NVTX (NVIDIA Tools Extension Library) and trace an MPI job execution as a timeline of API events per process using the profiler NVIDIA Nsight Systems. Code annotation libraries are activated by default in ABINIT when compiled on GPU, because NVIDIA CUDA Toolkit includes NVTX (and AMD includes ROCTX). As of ABINIT version 10.3.6, NVTX annotation is also supported on CPU (see with_gpu_markers input variable). A guide for minimal installation of selected NVIDIA developer tools required to use NVTX on CPUs is provided here. Note that we don’t need to install the entire NVIDIA CUDA Toolkit to profile code on CPU.
The NVIDIA Tools Extensions (NVTX) API can be installed on Linux with:
sudo dnf install cuda-nvtx-12
You can check the location of the installed library using the command locate nvToolsExt.
Environment variables must be set by adding the following lines to your .bashrc (assuming here version 12.8 has been
installed):
export PATH=/usr/local/cuda-12.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH
Nsight Systems installer can be directly downloaded from NVIDIA
website. We recommend to download the Full Version for
profiling from the GUI. A minimal installation for profiling from the CLI only is also available but not used here.
To use NVTX API you need to link ABINIT with nvToolsExt .so library and activate the NVTX markers macros. This can be
achieved by adding the following lines to your autoconf configuration file when compiling ABINIT on CPU with autotools:
with_gpu_markers="yes"
abi_gpu_nvtx_v3="yes"
GPU_LIBS="-L/usr/local/cuda-12.8/lib64 -lnvToolsExt"
Note that these lines are not needed when GPU is enabled because marker libraries are configured automatically from the CUDA library root. The serial profiler can be attached to individual MPI processes for generating a timeline of selected API events using the following command, for example here tracing MPI and NVTX events of a parallel ABINIT calculation:
mpirun -n 4 nsys profile --trace=mpi,nvtx path_to_abinit_exe path_to_input_abi
Once a report has been generated on your machine for each process, it can be opened (in single or multi-report view) in Nsight GUI with:
nsys-ui report1.nsys-rep
An output example of tracing NVTX/MPI API events on a single MPI process using NVIDIA Nsight Systems: